
|
|
Go to start page and Contents | Klaus Bung:
|
| 90 nabbe 91 ikyaa-nabe 92 baa-nabe 93 tiraa-nabe 94 cauraa-nabe |
95 pancaa-nabe |
Bright 1972, p 223, also had problems with his data (input) and eventually decided to base his analysis on one tape recording in which he had one native speaker recite the numbers from 1 to 99, followed by some discussion of the results with that speaker.
"The present paper will explore these questions with specific reference to Hindi, in the following steps: a complete set of numerals from one to a hundred will be presented; a morphological analysis of this paradigm will be attempted; and finally, the value of the analysis will be discussed. However, there is one difficulty at the start: namely, that many published sources give alternative forms for the Hindi numerals - and, indeed, virtually every source gives a slightly different set. For example, "67" is given variously as satsaTh (Harter 1960), sarsaTh (Kellogg 1938), and saRsaTh (Sharma 1958). The present description is based, to begin with, on the usage of a single informant on a single occasion: Miss Manjari Agrawal, a native Hindi speaker from Delhi, was asked to count to a hundred at a "normal" speed, and the results were tape-recorded and transcribed.
Subsequent discussion with Miss Agrawal revealed alternative forms in her usage - though not as much free variation as the published sources suggest. The attested variations will be taken into consideration at a later stage in this discussion; but first, let us consider the tape-recorded forms and their analysis.' "
The resulting data, which Bright used for his analysis, are as follows:

Click on image to make it larger.

Click on image to make it larger.
As far as the numerals from 90 to 99 are concerned, Bright agrees with the "aanve" version of Bailey and Firth.
Apart from many small variations, the one notable thing about Bright's list is that for 89 he uses the ekuna system (see below) rather than the counting-up system.
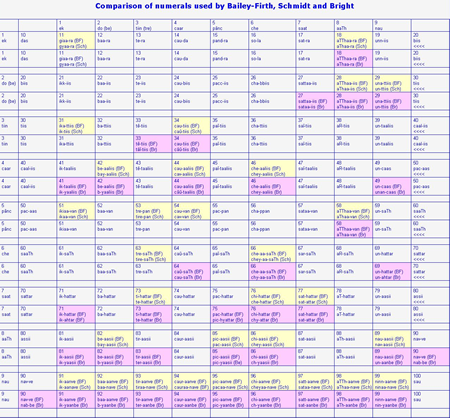
The following table compares Bailey-Firth with Schmidt and with Bright.
Click here to make image larger.
In this table, I have picked out the cells in which divergencies occur between Bailey-Firth and Schmidt by colouring them yellow. I have listed Bright's versions only where he differs from Bailey and Firth and have marked these cells in pink.
BF = Bailey-Firth 1956, Sch = Schmidt 1999, Br = Bright 1972.
Bright writes "eek" (1) and "chee" (6), where I write "ek" and "che". This vowel is /e:/ (as in German "geht"), which Schmidt writes as "e" with a bar. I have adjusted Bright's transliteration to fit in with mine.
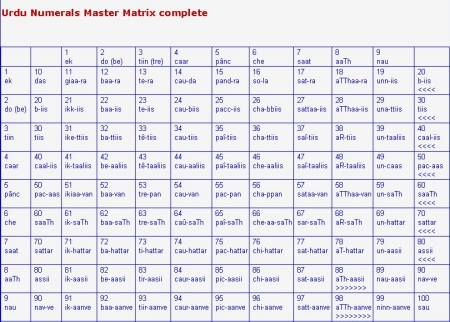
To make it easier to recognise a pattern in the numerals I have constructed a number matrix. My version of the numerals is taken from Bailey and Firth, 1956, p 20 f. The transliteration has been adjusted. Examples:
| Bailey and Firth | Klaus Bung |
| y | i |
| i | ii |
| w | u |
| u | uu |
| shwa | a |
| a | aa |
| &c | &c |
Click on the image to make it larger.
I have used a semi-phonetic notation, which I am as yet unable to type. For typing, I am using the following conventions:
For the compound numerals (from 11 upwards), I have marked the morpheme boundary (the boundary between the two elements) with a hyphen. I have tried to place that hyphen in such a way that the components in each row or column show as much regularity as possible. This will also facilitate learning.
Only once (in 66) I have postulated an "intrusive consonant" to ensure that the two remaining components remain as regular as possible.
In English numerals, from 13 to 19, the units (last digit) come before the tens (first digit); e.g. 13 = three-ten (not ten-three, as the digits suggest).
But this sequence is reversed as from 21; e.g. 21 = twenty-one (not one-and-twenty, as Jane Austen used to write).
Similarly "four and twenty blackbirds" in the old nursery rhyme:
Sing a song of sixpence,
A pocket full of rye.
Four and twenty blackbirds,
Baked in a pie.
In German, Danish, Dutch, Arabic and in Sanskrit, the "blackbirds sequence" is used for all numbers, and the same is the case in Hindi-Urdu.
So if we produce the number 28 in Hindi-Urdu, we first have to produce the appropriate form for 8 (in that context!), and then the appropriate form for 20 (in that context!). Both elements tend to be riddled with irregularities. Therefore the patterns to which I draw attention can only serve as memory aids for initial learning, but they are not sufficient to construct the numeral correctly.
| 9 nau |
The matrix has the numbers ending in 9 all in one column. 19, 29, ..., 79 all follow the same pattern. They all start with "un" (which signifies "minus 1" (or "one-to-go-till"), followed by the next multiple of 10. Therefore 19 is "-1 +20", 29 is "-1 +30", etc. |
| 19 unn-iis |
|
| 29 una-ttiis |
|
| 39 un-taaliis |
|
| 49 un-caas |
|
| 59 un-saTh |
|
| 69 un-hattar |
|
| 79 un-aasii |
|
Most numerals ending in 9 (namely the ekuna-numbers 19, 29, ..., 79) are not obtained by adding something to the next lower decad (e.g. in 24 we add 4 to 20) but by referring to the next decad up. So for 69 we do NOT think "9 plus 60", and then try to guess how to say 60. Instead 69 is expressed as "one to go till 70" (un-hattar). Similarly the other ekuna numbers:
19 = one to go till 20,
29 = one to go till 30, etc).
In these numbers the part containing "un" etc is comparatively easy, almost always the same, but predicting the correct variant of the decad is odd. The following is true of all ekuna numbers, except 49 (one before 50):
The decad, i.e. the second element of the number is not taken from the full decad but from the full decad plus 1.
Example: 39 (un-taaliis) does not take its second element from an unadulterated 40 (caaliis) but from the variant used in 41 (ik-taaliis) (etc). So 39 = un-taaliis.
Since the ekuna number below the full decad and the number immediately above the full decad pivot around the full decad, I have called these pairs "ekuna pivots". Here is a complete list of the ekuna pivots.
19 unn-iis 29 una-ttiis 39 un-taaliis 59 un-saTh |
69 un-hattar 79 un-aasii The great exception, |
Hindi-Urdu is not unique in this respect. Sanskrit, Greek, Latin (and no doubt other languages) behave similarly. I have listed below the examples which I am aware of. I would like to find examples in non-Indo-European languages; they must exist. I should be grateful to any reader who can send me examples.
Bernhard Comrie 1972, p xxx, states that ekuna numbers occur in many Slavonic languages, but I have been unable to find examples in any of the many Slavonic languages I checked. Perhaps they are less common alternatives to the counting-up system and the samples I have found did not include the alternatives. Again, I should be grateful to any reader who can send me examples.
We find the ekuna system in Sanskrit, but there is also a counting-up alternative available:
20 = vim-shati
19 =
(Source: Morgenroth 1989, p 103)
"na" = "not". This "na" is preserved in the various "un"-forms in Hindi-Urdu: unn-iis, una-ttiis, un-taliis, un-caas, un-saTh, un-hattar, un-aasii.
Assimilation produces: un-viis > un-niis > unnis (Berger 1992, p 253)
One could tabulate the approximate development as follows:
eko na viis ("one not twenty")
o na viis
o n viis
o n niis
u n niis
-----------
unniis
Whitney 1879, p 162, writes in detail about these forms, as follows:

Click on the image to make it larger.
Norman 1992, p 212, notes: "Although Whitney (1889: § 476) quotes navadaha for 'nineteen' in Old Indian, forms with ekona- are much more common. In Middle Indo-Aryan, navadaha is found only in Apabhramsa (Pp.). All other dialects have ekona-type forms."
The resulting phenomenon in modern Indo-Aryan languages is described by Berger 1992, p 253:

It is no great surprise that Gujarati, a sister language of Hindi-Urdu uses the ekuna system, even though its modern manifestation is much closer to Sanskrit than that of Hindi-Urdu. None of about 10 native speakers of Gujarati whom I asked to break down the word "oganis" (19) into its constituents ("Which part is the 10, and which part is the 9?)" could give me any answer, except that the word had to be learnt as a whole. Nobody ventured to suggest that my question was wrong, and that I should have asked "Which part is 20, and which part is -1 ?"
19 = ogan-iis
20 = viis
29 = ogan-triis
30 = triis
Gujarati
19 = ogan- iis
20 = v iis
29 = ogan-triis
30 = triis
eku na (Sanskrit)
oga n (Gujarati)
Waanders 1992, p 374, writes: "For "eighteen" to "nineteen" one also finds "duoin eikosi" ... and "enos eikosi" " (18 and 19 respectively), lit. "twenty lacking two/one."."
Früchtel 1948, p 40-41, first has a table showing the ordinary counting-up system for all Greek numbers, but then has the following remark:

(Click on image to make it larger.)
"Numbers which have been composed with 8 and 9 are often expressed by subtraction from the next full multiple of 10, with the aid of the participle "deoon, deousa, deon" = lacking (= showing a minus), e.g.
18 years: eikosin ete duoin deonta
(20 years two lacking)
19 years: eikosin ete henos deonta
(20 years one lacking)
59 ships: hexekonta ne'es mias deousai
(60 ships one lacking)
"
We are reminded of the English expression "pushing fifty" (etc), usually used of women who do not like to reach and transcend the next decade in their age.
20 = viginti
19 = un-de-viginti (one off twenty)
18 = duo-de-viginte (two off twenty)
30 = triginta
29 = un-de-triginta
28 = duo-de-triginta
etc up to 98, 99, 100
100 = centum
99 = un-de-centum
98 = duo-de-centum
Coleman 1972, p 397, quotes ekuna examples from Old English: "twaa laes twentig" (two under twenty = 18) and "aan laes twentig" (one under twenty = 19) among examples from Latin.
88 and 99 in Hindi-Urdu are not formed by the ekuna system, saying "90 - 1" and "100 - 1", but by the counting-up system, following on from their predecessors, (88,89) and (98,99).
