
|
|
Dr Klaus Bung Klaus Bung:
|
| 6 0 0 0 0 6 | copytyping |
| 6 0 0 0 0 7 | foreign language printing |
| 6 0 0 0 0 9 | e.g. research assistant copying quotations |
| 7 0 0 0 0 6 | copytyping |
| 7 0 0 0 0 7 | foreign language printing |
| 7 0 0 0 0 9 | e.g. research assistant copying quotations |
More complex activities, specified at resolution level
(21, 20, 29, 18, 28, 3, 2)
| 18 0 0 0 28 2 | writing of essays, reports, letters |
| 18 0 0 0 28 3 | free speaking; dictating essays, reports, letters; active parts of conversation |
| 2 0 28 18 28 2 | all kinds of copying and printing; same code into same or different |
| 2 0 28 18 28 3 | reading out aloud from all kinds of graphic code into all kinds of accents; including reading for the blind, transmitting written text over telephone ... |
| 3 0 28 18 28 3 | repeating spoken utterances, "translating" from one dialect into another |
| 3 0 28 18 28 2 | writing or typing from dictation (including shorthand), including taking of messages over the telephone |
| 2 28 18 18 28 2 | précis writing, preparing summaries of newspaper reports / letters etc.; getting the "gist" of written information |
| 2 28 18 18 28 3 | giving oral summary of written text, e.g. to top politicians, businessmen or blind persons of any kind; more important in country of target language |
| 3 28 18 18 28 3 | summarising speech, e.g. radio/TV reporter, including "translating" from one accent into another |
| 3 28 18 18 28 2 | preparing written summary of speech, e.g. newspaper reporter |
------------------------------------------------- page 9 ------------------------------------------------
Note: Groups 5 and 6 may have the same content as Groups 3 and 4 but with "unclear" (or noisy) inputs; only some extra examples are listed below. The ~ before the first number in each line indicates that an unclear input is referred to.
| ~2 0 28 18 28 2 | e.g. copying from bad handwritten script or typescript, with handwritten corrections; including research assistant copying handwritten documents |
| ~2 0 28 18 28 3 | reading letters for the blind |
| ~3 0 28 18 28 3 | passing on spoken message in ship's engine room or aircraft's cockpit; passing on telephone message from noisy line |
| ~3 0 28 18 28 2 | writing or typing telephone messages, taking dictation from noisy dictating machine |
| ~2 28 18 18 28 2 | writing down the gist of handwritten letters |
| ~2 28 18 18 28 3 | giving oral summary of handwritten letters |
| ~3 28 18 18 28 3 | non-verbatim passing on of mumbled or fast-spoken order or of order given in noisy conditions |
| ~3 28 18 18 28 2 | writing down gist of such information; part-skill of "consecutive" interpreter |
| 21 0 29 18 28 3 | translating written text orally, e.g. content of business letters over the phone to anticipate written confirmation |
| 21 0 29 18 28 2 | preparing written translations, variety of topics: commercial, technical, literary |
| 20 0 29 18 28 3 | simultaneous or intermittent interpretation |
| 20 0 29 18 28 2 | written translation of spoken text; input may be on tape or dictating machine; including on-the-spot translation of business correspondence into typewriter or into shorthand |
------------------------------------------------- page 10 ------------------------------------------------
| 21 29 18 18 28 3 | transmit gist of written text via foreign speech, e.g. tourist guide helping foreigner to understand a leaflet |
| 21 29 18 18 28 2 | writing summary of source language text into target language, e.g. "translation of gist" on margin of business letter so that action can be taken; this is most likely to be required in country of target language; the translator would then be a foreigner in that country |
| 20 29 18 18 28 3 | transmitting gist of spoken message orally, e.g. international telephone operator |
| 20 29 18 18 28 2 | composing a foreign letter of which only the approximate contents have been given orally in the source language |
| 2 0 28 18 29 20 | giving oral translation of foreign document, e.g. business letter or information for the blind |
| 2 0 28 18 29 21 | giving written translation of foreign document |
| 3 0 28 18 29 20 | oral translation of foreign speech; simultaneous interpretation |
| 3 0 28 18 29 21 | written translation of foreign speech, including taped message or telephone conversation |
| 2 28 18 18 29 20 | orally giving gist of foreign document, e.g. business letter for immediate action, or information for the blind |
| 2 28 18 18 29 21 | giving gist of foreign document in writing, e.g. note on margin of business letters |
| 3 28 18 18 29 20 | giving oral summary of foreign speech, especially intermittent interpretation |
| 3 28 18 18 29 21 | writing summary of foreign speech; including tapes of speeches and telephone conversations |
------------------------------------------------- page 11 ------------------------------------------------
Note: Groups 11 and 12 correspond to Groups 9 and 10 above but differ by having unclear inputs
| ~2 0 28 18 29 20 | handwritten or shorthand input |
| ~2 0 28 18 29 21 | handwritten or shorthand input |
| ~3 0 28 18 29 20 | input: fast speech, mumbled speech, speech in noisy environment: airplane, factory, ship |
| ~3 0 28 18 29 21 | as preceding vector |
| ~2 28 18 18 29 20 | Examples as Group 11, but unclear inputs and giving gist only |
| ~2 28 18 18 29 21 | |
| ~3 28 18 18 29 20 | |
| ~3 28 18 18 29 21 | |
| 2 0 0 28 18 30 | ability to respond to printed / painted commands / warnings by acting or refraining from action (foreign workers); in tests; making a drawing, tracing movements on a geographical map, assembling an object, ... |
| 3 0 0 28 18 30 | ditto: carefully spoken commands / warnings |
(with information reduction)
| 2 0 28 18 18 30 | as Group 13, but with highly redundant instructions, not every word of which is matched by an action |
| 3 0 28 18 18 30 | |
| ~2 0 0 28 18 30 | ability to act on handwritten commands / warnings; foreign workers; including ticking off of multiple choice answers |
| ~3 0 0 28 18 30 | ditto: carelessly spoken commands / warnings; factory / airport etc., noise |
(with reduced information)
| ~2 0 28 18 18 30 | Examples correspond to Group 14, but input is unclear, as in Group 15 |
| ~3 0 28 18 18 30 | |
------------------------------------------------- page 12 ------------------------------------------------
Note: "Non-verbal event into target" is restricted to vectors with reduced information because no description of events is ever *** absolutely *** complete. Unclear inputs (e.g. events in mist or fog) are excluded from consideration because the ability to cope with this variation is not a specific result of language training.
| 30 0 18 18 28 3 | oral description of pictures; sports reporter; describing real events |
| 30 0 18 18 28 2 | written description of picture or real events |
| 1 28 0 0 0 18 | e.g. silent reading; listening to radio, TV., theatre; receptive phases of conversation |
| 1 28 0 0 18 18 | ditto, with conscious information reduction (see Section 5) |
| ~1 28 0 0 0 18 | as preceding two vectors, with unclear inputs |
| ~1 28 0 0 18 18 | |
§ 28 We interpret the process of comprehension as an indirect transformation (in the sense of Ashby 1964) of utterance into meaning. With each utterance, a set of meanings is associated, ranging from the "full meaning" to meanings "reduced" in varying degrees by the usual processes of abstraction. For simplicity's sake, we describe this model with reference to handwritten utterances. The model can also deal with spoken utterances but some adjustments would have to be made, due to the transitory nature of the signals.
§ 29 We assume that the reader of a handwritten letter wants to get a certain amount of meaning (information) out of it, in some cases the full meaning, in some cases a reduced meaning. A greater fraction of meaning obtained is not always preferable to a smaller fraction of meaning. When trying to obtain precisely the fraction of meaning required for a particular purpose, the reader *** may *** sometimes obtain it at first reading (i.e. understand no more and no less than the information and detail required). More often he will either understand more and have to reduce the amount of information by discarding irrelevant details or he may understand too little at first reading and will have to return to the text to obtain more details. Moreover, he
------------------------------------------------- page 13 ------------------------------------------------
may at first, obtain a great deal of information but not from those parts of the message which are relevant to him. In brief, the reader has to search for the right amount and the right selection of information and to ensure its compatibility with the text, taking also into consideration other non-linguistic sources, such as his own prior knowledge, probabilities of certain events, intelligent guessing procedures (supported by parts of the text), etc.
§ 30 In addition, he has to be reasonably sure that he has achieved his goal in the three respects mentioned (right amount, right selection and compatibility). The degree of certainty required (in all three respects) varies in different circumstances and depends largely on the seriousness of the consequences of obtaining (and passing on or acting on) false information or too reduced information or too much information (e.g. failing an exam, causing a plane crash, causing serious losses on the stock exchange). It also depends on the time available for obtaining a greater degree of certainty.
§ 31 We assume that a reader knows more or less instinctively how much and which information he wants to obtain and how certain he wants to be that he has achieved his aim.
§ 32 Since the text may not be very readable, the reader often has to make a hypothesis about the linguistic form represented by the graphic signs. He then extracts the meaning of the hypothetical linguistic form or makes a hypothesis about a compatible meaning using extra-linguistic sources as well. If the amount of information obtained is too great, he can reduce it (this is a transition from 18 to 18). If the amount of information or his degree of certainty is not adequate, the reader uses the meaning obtained, together with his knowledge of the grammar of the target language, to reconstruct a linguistic form that expresses his hypothetical meaning (transition from 18 into 28) and compares the linguistic form with the given text (represented in our model by a transition from 28 into 1). The procedure sketched out here is presented in the form of a flowchart in Figure 2. Notation: "Do (a,b)" means that a transformation from "a" into "b" is to be carried out, i.e. an element of "a" is to be replaced by the corresponding element of "b".
+ and - mean "true" and "false" respectively.
------------------------------------------------- page 14 ------------------------------------------------
Figure 2:
 Click on the image to see the original flowchart of this procedure. Below you can see the same procedure presented as plain text with goto pointers. This presentation was created on 2010-04-16.
Click on the image to see the original flowchart of this procedure. Below you can see the same procedure presented as plain text with goto pointers. This presentation was created on 2010-04-16.
Step 1: Start
Step 2: Do (9,28), i.e. become conscious of some aspects of form.
Step 3: Do (28,18) i.e. use receptive grammar rules, guessing rules, etc., to cull out meaning.
Step 4: Sufficiently sure that understood meaning is compatible with message?
If yes, go to Step 5.
If no, go to Step 8.
Step 5: Too much meaning obtained?
If yes, go to Step 6.
If no, go to Step 7.
Step 6: Do (18,18), i.e. reduce meaning
Note: This is the only reasonable interpretation of (18,18) here, since a transformation without change would be useless, if not meaningless, and meaning cannot be increased without reference back to 28 or even to 9.
Go to Step 5.
Step 7: Adequate amount of meaning obtained?
If yes, go to Step 10.
If no, go to Step 8 .
Step 8: Do (18,28), i.e. use productive grammar rules to reconstruct message, utilising any form-fragment already clearly perceived
Step 9: Do (28,9), i.e. compare reconstructed message with actual signals. (To what degree do they match? Discovery of mis-matches may lead to a different hypothesis of underlying form or to hypothesis about additional part of underlying form)
Note: For the purposes of comparison, 28 is transformed, at least "in the mind's eye", into a spelling representation. This is distinct from both
28 and from the physical substance of 9. However, it is so close to 9 that I allow 9 to take its place in this description
Go to Step 2.
Step 10: Stop
------------------------------------------------- page 15 ------------------------------------------------
§ 33 This procedure describes such distinct activities as that of a copy typist trying to ascertain the exact wording of a badly written letter and that of an arbitrary person who only wants to get the gist of a letter for his own benefit. The copy typist starts with 9 and ends up with 28, before proceeding to transform 28 into 6. The "reader-for-the-gist" starts with 9 and ends up with 18, and may then, if he wishes, take appropriate verbal or non-verbal action, including that of reporting his findings in some language or other.
§ 34 The copy typist runs through the following cycle:
Figure 3
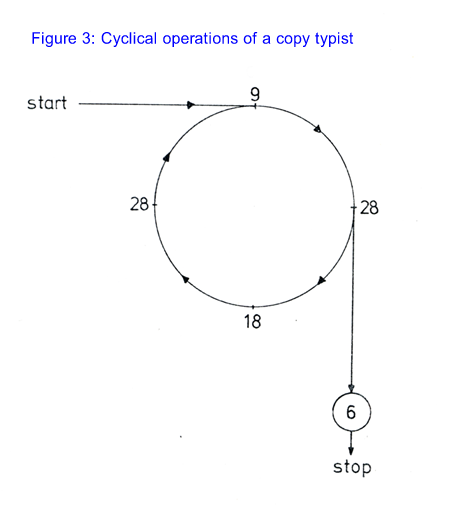
------------------------------------------------- page 16 ------------------------------------------------
§ 35 The potentially cyclic processes described here underlie all modules with an unclear inputs or information reduction. The vectors used for the representation of these modules abstract from the unlimited number of cycles permitted and show only the simplest case, i.e. that which occurs when the candidate happens to solve the task in a single transition through each component of the vector.
§ 36 This seemingly peripheral module has been chosen as an example for more detailed discussion even though it may not be of the greatest practical importance. The reasons for this choice are the following:
1 At first sight, the skill corresponding to the module seems to be so simple that nothing except ability to type in the source language seems to be required and thus nothing to be learnt or examined. The falsity of this first impression makes this module interesting.
2 There are in fact a great many things to be learnt in this module but they are quite different from, and much easier than, the usual content of foreign language instruction and therefore illustrate clearly the *** kind of *** gain that can be expected from the ideology underlying the projected units-credits system.
§ 37 This module, as opposed to "Group 3, Vector 2, ..., 2", presupposes that the given copy does not contain handwritten corrections and is free of error (e.g. the typist does not have to put occasional "obvious" misspellings right). When being trained for this skill, the typist acquires an intuitive knowledge of the transition probabilities among letters and of likely letter clusters and thus physical readiness to execute them. Moreover, knowledge of certain basic spelling conventions can be helpful (e.g. capitalisation after certain punctuation marks).
§ 38 There may be formal rules for splitting words at the end of a line. If there are no formal rules, then it may at least be possible to find and teach rules which reduce the probability of error. Note that the teaching target is never error-free performance but consists of the reduction of the probability of error below a certain value that may vary in different situations. Therefore even false rules are acceptable provided they produce the desired effect.
------------------------------------------------- page 17 ------------------------------------------------
§ 39 If the rules for the splitting of words presuppose knowledge of the meaning of the language (and therefore go beyond the limits of this module), the typist can benefit from knowing which dictionaries clearly indicate potential splits in each word (e.g. Hornby's "Advanced Learner's Dictionary of Current English") and by understanding the relevant typographic conventions of such a book (e.g. formerly in Hornby a distinction between "-" for potential split and "=" for obligatory hyphen).
§ 40 Without such skills, the learner may have to avoid all splits. However, this strategy will not help in cases where a word has been split in the original copy but cannot be split in the second copy because it occurs, say, at the beginning of a line. Here, the typist must be able to determine whether the "-" in the original copy stands for a hyphen cum split-mark or only for a split-mark and accordingly copy or not copy it.
§ 41 This problem cannot be avoided by instructing the typist to make each of his lines identical in content with the given copy, since the original typewriter and the copying typewriter may have typefaces of different size (e.g. Pica versus Elite).
§ 42 The foreign language may have special signs which are not on the typewriter keyboard of the copy typist. Usually there are established conventions of substitute signs to be used in such cases. Sometimes the substitute signs are constructed by overtyping. Here are some examples: where a special sign for the digit "one" is not available, the first letter of "lovely" and not of "Isidora" is used as a substitute; thus:
l500, not I500, but ideally 1500. Where the dollar and cent signs and certain Scandinavian vowel letters are not available, the oblique stroke is used in conjunction with available letters to construct ![]() from o with / ,
from o with / , ![]() from S with / ,
from S with / , ![]() from c with /
from c with /
On the other hand, where the £ sign is not available, the accepted substitute is not
![]() L with / (which I have seen in a Spanish publication) but
L with / (which I have seen in a Spanish publication) but ![]() , L with = .
, L with = .
The French cédille can be constructed by typing a comma over a "c", thus:
![]() , instead of the ideal ç .
, instead of the ideal ç .
German umlauts can be constructed with the help of double quotation marks over lower case letters, e.g. o "![]() is their quotation mark substitute for ö. But on capital letters, the quotation marks must be moved up by half a line so that we obtain
is their quotation mark substitute for ö. But on capital letters, the quotation marks must be moved up by half a line so that we obtain ![]() and not
and not ![]() for Ö . The German "es-zet" (ß) may in emergencies be
for Ö . The German "es-zet" (ß) may in emergencies be
replaced by ss or sz but not, as often happens, by B. In German typescript,
" _____ " is it acceptable even where the printed or handwritten original has
„_____ ". (opening quotation mark at line level instead of above line level).

Click on image to make it larger.
§ 43 Ignorance of such devices is very widespread among typists and its eradication could greatly facilitate work not only in offices where straightforward foreign language copy typing has to be done but even in the much simpler situations where an office has to cope with a comparatively large number of foreign names, addresses, currencies and book titles while the
------------------------------------------------- page 18 ------------------------------------------------
correspondence itself is conducted in the typist's native language. In such cases it is hardly worthwhile to employ an expensive secretary with knowledge of foreign languages but a person with the skills described above would be highly desirable. (Note that the ability of transferring foreign addresses correctly from a letterhead to an envelope is also not a trivial matter, quite apart from the will lettering problems discussed above.)
§ 44 We treat conversation in the view of any one partner as a sequence of alternating active and passive phases. The active phases of conversation are accounted for in Group 2, Vector (18, . . ,3 ), p. 8. The passive phases of conversation have so far not been assigned modules of their own since they and in 18 (perception of meaning) and their output is therefore not observable and examinable. However, transitions from 3 to 18 (representative of the passive phases of conversations) do occur as constituents of other modules to which observable outputs have been assigned, e.g. in Groups 3 to 6 and 9 to 14.
A thorough study of the significant features of conversation tests will be made with a view to fitting a comprehensive conversational module into the system.
§ 45 I shall now
------------------------------------------------- page 19 ------------------------------------------------
Ashby, William Ross 1964: "An introduction to cybernetics". Methuen, London, England
Kelley, John L. 1960: "Introduction to modern algebra". Van Nostrand, Princeton, New Jersey, USA
Klír, Jiři, and Miroslav Valach (Jiri Klir and Miroslav Valach) 1967: " Cybernetic modelling". Iliffe Books, London, England '
Mangoldt, H. von 1965: "Einführung in die höhere Mathematik" (Introduction to advanced mathematics). Vol. 1, 12th Edition. Hirzel Verlag, Leipzig, Germany
Trim, J.L.M. 1969: "Specifying the linguistic and behavioural content of language skills". In: Centre for Information on Language Teaching, Reports and Papers, No.2: "Aims and techniques: language teaching methods and their comparative assessment", pp. 17-21. Centre for Information on Language Teaching, State House, High Holborn, London, WC2, England
© 1973 and 2010 Klaus Bung
eof





