
|
|
Dr Klaus Bung Klaus Bung:
|
| 1 |
Memory consists of an infinite number of 'layers' in which information may be stored. |
| 2 | Every layer is characterised by a specific retention span (decay time (cf 'half life')). |
| 3 | During learning, items of information drift or jump typically from layers with short retention spans to layers with longer retention spans - in the graphic presentation from 'higher' to 'lower' layers. |
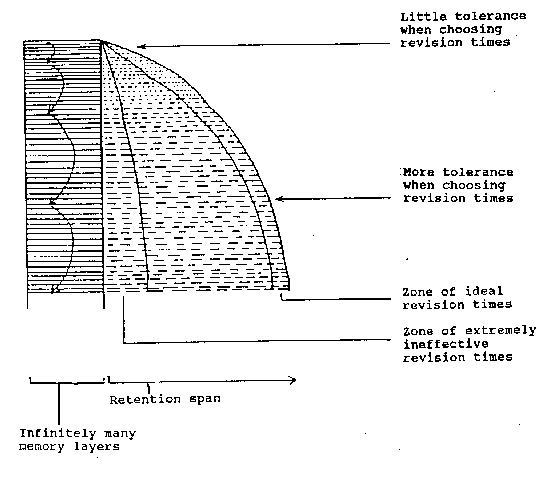
Diagram 1: Infinitely many layers of memory
| 4 | The drifting / jumping from higher to lower layers is effected by revisions. (The term 'revision' is also meant to cover tests and initial learning, the latter being, in a way, less important than revisions. In DYNAMIC LANGUAGE LEARNING, initial learning, revisions and tests are identical. All learning events are occasions for testing and diagnosis with consequences for further learning procedures. All tests are primarily learning events. Initial learning is that brief event which places an item of information into memory for the very first time.) |
| 5 | The retention span grows with each layer, but its rate of increase decreases with each layer. Whether the rate of increase ultimately falls to zero is not certain, but this is our working hypothesis. |
| 6 | Several adjacent layers are called a 'region'. |
| 7 | We can estimate in which region an item of information has been stored but we can never determine exactly in which layer it is stored. That is the "uncertainty principle" in the Theory of Dynamic Learning Algorithms. Example: Assume that layer L(i) has a retention span of m minutes. If a test takes place m minutes after the previous test and item X can still be recalled (correct response), we know that X was stored either in layer L(i) or in a lower layer, but not in which layer. The actual storage layer may, but need not, be far from layer L(i). We cannot determine the position of the actual storage layer more precisely by a further test, since the test itself will alter the state of memory, i.e. the information will unavoidably move to a different layer. If, in our original test, the item could no longer be recalled (incorrect response), we know that it was stored in a higher layer. For practical purposes this means that the interval before the next revision must definitely be shortened; but it is not certain by how much. |
| 8 | Tests cannot determine where an item of information is stored but only where it is not stored. |
| 9 | If an item of information is not revised before the end of the retention time, it decays. (If an item has decayed, the learner will, during a test, make a wrong response.) Whether it leaves any traces is a different question. |
| 10 | If an item of information is revised before its retention span has expired, it jumps into a lower layer. |
| 11 | The size of the jump depends on how close the time of the revision is to the end of the retention span. Immediately before the end of the retention span, the jump will be largest. Immediately after the beginning of the retention span the jump will be neglegibly small. |
| 12 | For practical purposes this means that revisions should, as far as possible, be put into the zone shortly before the end of the retention span. This will not only maximise the effectiveness of the revisions (size of jump) but also the interval between revisions, which in turn minimises the number of revisions necessary. |
| 13 | Moreover the size of the jump depends statistically on the location of the take-off point, i.e. on which layer the item is stored in when the jump takes place. The jumps from the higher layers are usually smaller than those from the lower layers. |
| 14 | For practical purposes this gives us an indication as to where we must assume the end of the next retention span to be, i.e. at what time or on what date we have to plan the next revision. |
| 15 | The length of any given retention span cannot be determined with certainty. When deciding on the revision times, we are therefore in the position of someone walking blindfold towards an abyss (the abyss of forgetting). If we place the revision too soon, the system of revisions is not as economical as it might be. If we place the revision too late, the information will have been forgotten, the time required for the revision increases and, again, the revision system is not as economical as it might be. In trying to remain between the two uneconomical alternatives, we are navigating between Scylla and Charybdis, treading the Middle Path, sharp as a razor's edge (Katha Upanishad, I, 3, 14). |
| 16 | This dilemma is called 'Brinkman's Gamble' or 'The Brinkmanship Syndrome' (in German, the 'Spätlese-Effekt'). Spätlese is expensive high-quality wine made of grapes which have been kept on the vines for as long as possible to expose them to a maximum of sunshine but avoiding the damage the first frost might do them. The later the grapes are harvested, the better the wine. The wine-grower does not know for certain when the frost will come. If he picks the grapes too early, they are less sweet. If he waits too long to harvest them, they may be destroyed by frost. |
| 17 | For practical purposes this means that we make the system as economical as possible by moving the revision times as close as possible to the suspected abyss. In those cases where the revision turns out to be too late (i.e. the item has been forgotten), we correct our error in placement by using the so-called 'SAFETY-NET ALGORITHM' ("Shortening Algorithm") ("special measures"), which systematically shortens the intervals of future revisions for the items in question. |
| 18 | The efficiency of the revisions depends on how accurately we estimate the layer in which an item of information is stored. In DYNAMIC LEARNING these estimates are made by the so-called retention algorithm. |
| 19 | The co-operation between RETENTION ALGORITHM and SAFETY-NET ALGORITHM ("Shortening Algorithm") is a dynamic compromise, whose aim it is to make the SAFETY-NET ALGORITHM as superfluous as possible (i.e. to trigger it as seldom as possible), but not to go so far in this effort that the RETENTION ALGORITHM becomes decidedly uneconomical (most revision intervals too short). |
| 20 | The underlying principle of these two algorithms is as follows: During initial learning and during each revision, the RETENTION ALGORITHM determines for each item of information (task, word, sentence fragment, sentence, grammatical rule) when the next test and the next revision is to take place. As a matter of principle, the intervals between revisions become larger. But if, for any item of information, the RETENTION ALGORITHM has gone too far, then the 'SAFETY-NET ALGORITHM' shortens the intervals for this item. As soon as the revisions of this item yield correct answers again, the RETENTION ALGORITHM takes over and lengthens the intervals. |
| 21 | Because of the effect the algorithms have on the intervals between revisions, the retention algorithm and the safety-net algorithm could also be called STRETCHING and SHORTENING algorithm respectively. |
| 22 | The dynamic tennis game between RETENTION ALGORITHM and SAFETY-NET ALGORITHM continues until the learner has reached the retention span agreed with him as his target standard and until he has proved his mastery by means of a test. |
Dynamic Learning Algorithms enable the learner to learn information in unlimited quantities and remember 90 percent of it for as long as it remains useful for him.
The concept of 'unlimited quantities' is based on research by Helmar Frank, who has shown that on the one hand the human input channels (eyes, ears, ...) are so limited and on the other the capacity of human memory is so great that the span of human life (e.g. 100 years using all channels day and night at maximum capacity) is not sufficient to fill the storage capacity of human memory. Therefore, if there is a limit to the ability of man to learn, it does not consist in the capacity of human memory, but in the time which he has available for learning. What we learn, we can remember. The amount that we can learn is a function of time.
In the theory of Dynamic Learning, 'usefulness' is defined subjectively and pragmatically: It is only worthwhile to learn information which one needs so frequently or so quickly that the sum of all look-up operations (e.g. 50 times per year) costs more time than learning and practising that information.
Example
Telephone numbers which we need frequently we will, in the end, remember without memorising them. If a phone number is rarely needed, it does not pay to memorise it. Lawyers, programmers, builders, and members of other professions can provide similar examples. The ability to forget is almost as important as the ability to remember.
In one of his short stories, Jorge Luis Borges, the Argentinian writer, has explored the awful fate of a man doomed to forget nothing, not even the smallest detail, i.e. a man unable to distinguish between important and unimportant, useful or useless:
'Funes no sólo recordaba cada hoja de cada árbol de cada monte, sino cada una de las veces que la había percibido o imaginado.' (Funes not only remembered every leaf on every tree on every mountain but also each of the occasions on which he had perceived or imagined them.) (Borges 1965, p 51)
It is one of the strengths of the theory of Dynamic Learning that it offers a proper function to the phenomenon of forgetting rather than treating it merely as an aberration, the sin against the Holy Ghost, for which there can be no forgiveness (Mark 3:29).
Just as the theory of Dynamic Learning takes the Middle Way between revising too soon and revising too late, it takes the Middle Way between remembering too long (or too much) and remembering not long enough (or too little).
In the theory of Dynamic Learning we have defined as useful those items of information which the learner needs at least once every four months. Useful information is therefore revised at least three times a year ('natural revisions') - by being used in practical life (work, travel, etc.). The subjective usefulness of an item of information can change during the course of one's life (e.g. when changing one's job). In that case subjectively useless items of information are rightly forgotten. Later they can, if needed, be activated again.
The natural revisions take place at times which usually are unsuitable for learning new information (usually too far apart).
The Dynamic Learning Algorithms therefore ensure by means of 'artificial revisions' (planned revisions) that the items to be learnt reach a memory layer in which they can be stored sufficiently long for the natural revisions to become effective.
MEM increases the memory span systematically from a few seconds or minutes to four months. Each natural revision (at least once every four months) extends retention by a further four months or more.
As soon as the natural revisions occur less frequently than that, it proves that the information in question is no longer useful. It will therefore be forgotten. As soon as the learning algorithms cease their activity, the Darwinian principle of 'natural selection' (survival of the useful) comes into play. Useful information is retained, useless information is forgotten.
The revisions (those within one learning session and those distributed over days, weeks and months) are triggered by MEM when, according to the memory model, the learner is still able to make 90% correct responses. In other words, we revise before rapid forgetting starts.
In industry, the strategy customary in schools is called 'breakdown maintenance': MEM's strategy is called 'preventive maintenance' (planned maintenance). Preventive maintenance is generally recognised as the better strategy.
The number 90 (90 percent) is of critical importance, and revising at this time has several advantages:
| 1 | Revisions in accordance with this principle give the learner an experience of success. They show him how much he has retained, whereas the typical revision at school shows him how much he has forgotten. Therefore he likes doing the MEM revisions and they, in turn, increase his performance. This is the opposite of the vicious circle practised in schools: revision exposes failure, is therefore unpleasant, is therefore avoided, resulting in more failure. This aspect of the revisions also creates MEM's greatest strength: 'motivation by success' (by contrast with external motivation, which can, for instance, be created through dressing the subject matter in game-like activities, variation in approach, etc). Teachers are not sufficiently aware of how well learners respond to motivation by success because there is so much failure in schools and it is so difficult for them, with conventional means, to offer and guarantee success continuously. |
| 2 | Every revision is subject to the same rules (algorithm) as initial learning. Dynamic Learning does not differentiate between initial learning and revision or between learning and testing. In each case the algorithm allows the learner to practise his skills until he can give 100% correct answers with the prescribed retention span. It takes less time to bump up the performance from 90% to 100% than to do so from 20% to 100%. Therefore if the revisions take place at the 90% point, they take less time than if they are done at times below that point. Example: An exercise designed to teach ten words in a foreign language may take one minute during such a revision, i.e. the time that has to be invested for such revisions is tiny. It is therefore wrong to revise too late. |
| 3 | The effect of revisions at the 90% point is illustrated in Diagram 2. |

Diagram 2: Curves of forgetting
The curve of forgetting R0 (Revision 0 = Initial learning) is roughly based on Ebbinghaus's work: Most of what we have learnt on any one occasion will be forgotten within the first two days. So, on Day 3 or 4, the retention rate may be 10% or 20%. A revision starting from that basis is very time-consuming. ('Revising' means to 'bump' the success rate back up to 100%.) But if we start 'bumping' at 90%, the success rate of 100% will be restored very fast. ClarificationDistinguish 'success rate' from 'retention rate'. During a revision session, the first pass through an exercise demonstrates the retention rate: If the student gets 90% of his answers right during the first pass, he has demonstrated a retention rate of 90%. The timing of the revision session is designed to ensure that this retention rate is achieved. If the retention rate was less than 100%, the student makes further passes through the exercise until gives 10 correct answers in succession. Each pass through the exercise yields a success rate, usually equal to the first or increasing, until the prescribed target success rate of 100% has been agreed. The retention rate is a 'success rate coupled with a specific retention time', the 'success rate' is measured unconditionally, the percentage of correct responses regardless of the length of time that has elapsed since the last pass through the exercise. In Dynamic Learning the student continues practising an exercise (passing through it from item 1 to item 10) until his success rate is 100%. This rule, combined with the algorithmically controlled timing of the revisions, ensures that the retention rate is on average 90% or better. Every revision (R1, R2, ...) results in a new, flatter, curve of forgetting. After each revision it takes longer for the success rate (retention) to fall back to 90%. The learning algorithm continues to work until the curve of forgetting has become so flat that even after four months a success rate of 90% can be guaranteed. (In practice, the success rate is usually higher.) |
|
| 4 | It would also be wrong to revise too early (or too frequently). If the revision comes too early, it makes the increase in the retention span unnecessarily small. In an extreme case (e.g. if the learner tries to learn by copying a foreign language word a hundred times or by murmuring it ten times in succession [necessarily without thinking]), the 'revision' (here repetition) has no effect at all, even though in this case, for once, 99.99% correct responses can be guaranteed. Nevertheless even such revisions cost time, however little. Revisions which come too soon produce too little and cost too much. |
| 5 | For learning and revisions to be effective the learner must at least have a chance of making mistakes, namely a 10% chance. That makes him concentrate on his work. Thoughtless 'practice' brings no results. Mistakes are useful: like spice in food, like poison in medicine or evil in the world - provided they are correctly diluted. |
| 6 | There is a trading relationship between the number of revisions and the time required for each revision. We will illustrate that with an example. ExampleIf I shorten the intervals between revisions by doing more revisions, I will make fewer mistakes during each revision session. Therefore the time invested per session will decrease, but each additional session costs time. The total time invested thus sinks by the shortening of each session but grows by the increase in the number of sessions. Starting point: Revision sessions too infrequent, total time therefore too great. As soon as I begin to revise more frequently, the total time is reduced. It is reduced each time I add another revision and thereby decrease the interval between revisions. After a while, however, there comes a point (the 'trough' of minimum time) at which additional revisions cause the total time to increase. Assume a revision with a 100% success rate requires 45 seconds (e.g. a vocabulary exercise consisting of ten words). That is the time one needs in order to write or type the exercise. It is impossible to shave anything off this time. Therefore, if the learner has reached the level of 100% correct exercises and nevertheless shortens the intervals (instead of lengthening them, as MEM does), then each additional revision costs at least 45 additional seconds, but brings no gain in learning. |
| 7 | The popular advice 'Revise as often as possible' is therefore irresponsible and childish. A pupil who follows this instruction will, in theory, revise either too often or too little, in practice, however, almost always too little. What is necessary will seldom seem necessary to him. A teacher is irresponsible or ignorant if he does not tell his pupil how often he should revise. It is childish to think that one cannot revise often enough or that one cannot revise too often. If the teacher does not tell the learner exactly how often he has to revise, the learner will revise too little. If, however, the teacher gives the learner exact instructions, which patently and always lead to success, he will carry them out, i.e. he will revise more often. A teacher who makes impossible (sic!) demands on his pupil ('as often as possible'!) will receive not even what is possible. (The maxim 'Demand the impossible in order to achieve the possible' obviously does not apply in this case.) The theory of Dynamic Learning counters the 'As often as possible' with the following principle: "Revise as seldom as possible and as often as necessary". The algorithm behaves responsibly since it tells the learner exactly how many revisions are necessary and when he has to carry them out. Georg Christoph Lichtenberg (1742-1799): 'Wo alle Leute so früh als möglich kommen wollen, da muß notwendig bei weitem der größere Teil zu spät kommen.' (If everybody were satisfied with coming as early as possible, then most people will necessarily be late.) It is better to arrive 'punctually' than to come 'as early as possible'! It is better to revise as often as necessary than to revise as often as possible. |
The theory of Dynamic Learning Algorithms stands out by the following features:
One of the simplest and cheapest possibilities of benefitting from the Dynamic Learning Algorithms is the computer program MEM. It is to learning what the wordprocessor is to writing.
The computer program MEM, which implements the Dynamic Learning Algorithms, will be offered under licence to publishers (and possibly textbook authors) (or nowadays (2010 AD) to members of the Open Source Community). Even if they are inexperienced in the use of computers, they can couple MEM with existing textbooks or fit MEM as a 'learning engine' into existing courses or into courses to be newly developed. It is thus possible to create computer-based teaching materials in large quantities, for many different subjects and at very low cost. Cost and efficiency are predictable.
The following subjects can benefit from MEM:
MEM enables the course author to utilise all types of exercise which occur in textbooks. Unlike textbooks MEM not only supplies information but also practises it with the learner and ensures that the learner remembers it and can reproduce it. The author does not have to do any programming: typing skill is all that is required.
In addition, MEM has a reading mode. In this mode, the monitor displays a foreign language text (e.g. Homer, Cicero, Chaucer, Shakespeare, or any modern text that is useful for study) and the pupil can, at a keystroke, call up the translations of the current word from MEM's electronic dictionary.
This facility offers at least the following benefits to learners:
MEM contains a wordprocessor (MEM-Writer). Pupils can use this to write and correct foreign language compositions and also can, at a keystroke, access MEM's electronic dictionary.
MEM's PersEx-Strategy (personalised explanation strategy) offers the learner explanations (an exposition) concerning a subject matter. This is followed by a diagnostic question. Depending on the answer given by the learner, he receives corrections or further explanations.
Where computers are in short supply, MEM can be used by groups of students (up to four persons per machine).
MEM has been incorporated into my course 'English with computer-bias' (Christiani-Publishers, Konstanz, Germany). This is a multi-media correspondence course for Germans wanting to learn English. MEM functions as the 'engine' (learning engine) in this course.
The course
Cheating is revision
at an incorrect time.
Even 'cheating' during a test or examination finds its place in the theory of Dynamic Learning. Cheating during a test or examination is in fact a form of revision but at a time not prescribed by the Dynamic Learning Algorithm. Correct responses obtained through cheating therefore mislead the teacher (teaching system) and therefore make it impossible to take the proper remedial action provided in the system for wrong responses, e.g. to give further instruction and practice and to reduce the interval before the next revision.
When assessing the results of a test, the teacher (examiner) must expect that his students have done an 'unauthorised' revision during the last five minutes before they enter the classroom (examination hall) . If they give correct answers he can therefore at best be sure that they have demonstrated a retention span of, say, 30 minutes. The teacher (examiner) would like to, but cannot, prevent that unauthorised revision since what he wants to test is a much longer retention span. Ideally the student does all, and only those revisions which have been prescribed by the system. But in practice the teacher cannot prevent this unauthorised revision. To that extent the unauthorised revision before the start of the test is similar to 'cheating'.
If students cheat by copying from a book kept under their desk or from a classmate's work (etc) they have to retain the copied information in memory for half a minute or a minute. A correct answer therefore testifies to that short retention span.
The need to cheat and the ability to cheat do not necessarily imply total ignorance: some knowledge of the subject matter is usually required even for successful cheating. Without such knowledge, the student might not know where and what to copy. If he had to copy complex chemical formulae, he might not be able to do so during the seconds when he has a chance to cast a glance at the prompt. Therefore correct answers obtained through cheating do testify to some knowledge. But that knowledge is not sufficient.
Learning begins with instant repetition (copying in speech, writing or any other action).
Once the learner can copy a subject matter element (e.g. repeat a word or a sentence, etc), he proves thereby that he has retained it for at least one second (i.e. in the upper-most layer of memory). If he cannot copy it, it has not even landed in the upper-most layer. The activities which are generally called 'revision' (and treated as a different matter) are in fact identical with instant repetition. The only difference is that the retention span is longer. But the mechanisms are the same.
The technique of teaching and learning consists in the efforts to obtain correct responses after a reasonable interval of time (retention span).
We obtain correct responses by making the retention span short enough, i.e. by shortening it step by step until correct responses start coming.
If we have reduced the interval to a few seconds (and thus are practising instant recall) and if nevertheless correct responses will not come, then we have to simplify the task itself. The desired initial retention span has to be further shortened by shortening the subject matter element, simplifying it or letting the learner do preliminary exercises. At this stage the non-algorithmic factors, such as those listed at the beginning of this paper, are important.
| 1 | In the teaching of English to foreigners (absolute beginners): If the learner cannot repeat the word 'afternoon', we explain and practise its elements 'after' and 'noon' one by one. The retention span will then be shorter and the demands made on the learner's memory will be less. If the learner cannot even remember for 20 seconds that 'why' in Sanskrit is 'kimartham', I begin by teaching him gradually the following 'equations': If the pupil finds the 9 letters of 'kimartham' too difficult, I first start with the 3 letters of 'kim'. If even three letters are too difficult for him, I start by teaching him that question words (interrogatives) in Sanskrit start with 'k'. Once he has learnt that, he lacks only two letters on the ladder to success. Hypothesis: If willing pupils do not learn, it is usually the fault of teachers or textbook authors and of their impatience or their prejudices. There is no subject matter which could not be made even easier. |
| 2 | If the pupil cannot even repeat (orally) the short word 'after', we let him copy the word in writing or let him translate it in writing. Sometimes we can give him memory aids, relating the word to his native language. German learners of English can be reminded that English 'after' is related to the German word 'der After' (anus). For pupils who can write, and especially for adults, writing is easier, because it gives them time to think and because every letter can be practised individually. As sentences consist of phrases and phrases of words, so words consist of letters. Phrases are easier to learn than sentences, words easier than phrases and letters easier than words. (Where needed, MEM can be switched down to the level of learning letter by letter.) Contrary to the claims of educational dogmatists and traditionalists, in foreign language teaching, especially with adults, it has become apparent time and again that learning is more efficient (takes less time) if the learner first practises in writing before practising the same material orally. Classroom experience is in this case clearly superior to the popular theory. Most adherents of the popular theory (to let learners, at any price, practise speaking before writing) have never themselves tried the opposite approach seriously and with all due precautions. The theory is a prejudice. It is time to check the validity of the popular theory thoroughly rather than repeat it naively, and with incomplete arguments, and thus pass it on to one generation of teachers after another. |
| 3 | As soon as a learner can instantly repeat a subject matter element, the battle has been won. The element is now stored in a memory layer with a very short retention span. Now it has to be repeated before the retention span has expired, e.g. after 5, 10 or 20 seconds. |
| 4 | In order to avoid experiences of failure (which kill motivation), the teacher or program must try to find an entry to learning which enables the learner from the very beginning to make as few mistakes as possible, rather than moving down to the correct level of approach only after many mistakes. |
| 5 | Now the subject matter element has to be anchored more firmly in memory. We therefore revise it at ever increasing intervals, and always before the retention span expires. What is important is therefore not only the right number of revisions (which B F Skinner rightly demanded), but also the correct time for each of these revisions (which is the novel feature of the theory of Dynamic Learning). These times are different for each learner and for each subject matter element. = We therefore need Every teacher can ensure that the learner fails a test or makes a wrong response. All he has to do is ask at the wrong time. Correspondingly, every teacher can make sure of correct responses by asking at the right time. By manipulating the timings skilfully he can lead his pupil safely to correct responses and long retention times. By fixing the revision times correctly, the Dynamic Learning Algorithm (or the program, the teacher or the pupil following that algorithm) can guarantee that what has once been learnt ( = correctly copied) is never forgotten. If these principles are correctly applied, any subject matter, however difficult, will, given the required amount of time, yield to the Dynamic Learning Algorithm. |
'On this path,
no effort is ever lost,
and no obstacle prevails.'
(Bhagavad Gita, 2:40)
Borges, Jorge Luis 1945: 'Funes el memorioso' (Funes, the memory acrobat). In: 'Ficciones'. Quoted from: Jean Franco (ed): 'Cuentos americanos de nuestros días' (American stories from our time). Harrap, London, 1965, S 46-52
Bung, Klaus 1967: 'A model for the construction and use of adaptive algorithmic language programmes', in M J Tobin (ed): 'Problems and methods in Programmed Learning', p 108-114. Proceedings of the 1967 APL/NCPL Birmingham Conference, Part 1. Birmingham: The National Centre for Programmed Learning, School of Education, University of Birmingham), England
Bung, Klaus 1972: 'Teaching algorithms and learning algorithms'.In: PROGRAMMED LEARNING AND EDUCATIONAL TECHNOLOGY, Vol 19, No 3, p 181 - 218, London, 1982 (Text of a paper presented and distributed at the Conference for Educational Technology at the University of Bath, England, in 1972, but, because of its length, published only ten years later.)
Bung, Klaus, and Milos Lansky 1978: 'Educational cybernetics'. In: Derick Unwin and Ray McAleese (eds) 1978: 'The encyclopaedia of educational media, communications and technology', p 266-307. Macmillan Press Ltd, 4 Little Essex Street, London WC2, England
Bung, Klaus 1986: 'Educational programs for microcomputers from the publisher's point of view'. Mimeographed. Distributed to Members of the Publishers' Association, London, England. English and German versions available. Recall Training Consultants Ltd, 68 Brantfell Road, Blackburn BB1ö8DL, Lancashire, England
Bung, Klaus 1991: 'Englisch computer-orientiert' (One year multi- media correspondence course for German beginners learning English.) Uses subject-matter algorithms and learning algorithms, oriented towards texts dealing with computers. Media: Paper, worksheets, interactive computer programs, 36 audio-cassettes. Publisher: Fernlehrinstitut Christiani, Konstanz, Germany, 1991
Bung, Klaus: 'Dynamic Language Learning. A textbook for learners.' (In preparation)
Ebbinghaus, H 1885 (sic!): 'Über das Gedächtnis' (On human memory). Leipzig
Frank, Helmar 1969: 'Kybernetische Grundlagen der Pädagogik' (Cybernetic foundations of education). 2 Volumes. Baden- Baden, Germany
The references to cassette recorders and IBM compatible computers were relevant to the hardware available at the time of writing. Hardware has changed and become much more flexible than it was then, but human psychology, the main topic of this paper, has remained unchanged, and is often not taken sufficiently into consideration when teaching materials are developed for computers, which are now capable of doing anything that is asked of them. That makes such software less efficient than it could otherwise be.
We are now working on ways of transferring the psychological procedures used with cassette recorders to mp3 files and are looking for members of the Open Source Community to develop the necessary universal control software.
The German publisher (Christiani) who published the very successful first public implementation of Dynamic Learning Algorithms in a sumptuously produced computer-based course teaching English to German adult beginners, which was a best-seller in Germany at the time and earned me a fortune, was taken over by a company which had no interest in foreign language publications. Therefore this particular product (German>English) disappeared from the market and the great plans I had with Christiani (with whom I had a wonderful personal relationship) to use the same psychological model and the same universal software (MEM) to produce courses in all possible combinations of languages
English>German
English>French
French>English
French>German
German>French
Proto-Hittite>Proto-Anatolian :-)
were never realised. I am still looking for partners (commercial or in the Open Source Community) with whom these projects can be realised so that the profound insights of this research can be saved for, and transmitted to, posterity and benefit the many eager learners alive now.
eof


{kind=link}